HEAP
Heap adalah pohon complete binary tree biner yang berdasarkan memenuhi properti heap.
Apa jenis properti heap?
Min Heap:
Unsur setiap node adalah lebih kecil dibandingkan anak-anak.
Max Heap:
Unsur setiap node adalah lebih besar dibandingkan anak-anak.
Min-Heap
Ini menyiratkan bahwa elemen terkecil terletak pada akar pohon.
Unsur terbesar terletak di suatu tempat di salah satu node daun.
Heap dapat diimplementasikan dengan menggunakan linked-list, tapi jauh lebih mudah untuk menerapkan tumpukan menggunakan berbagai.
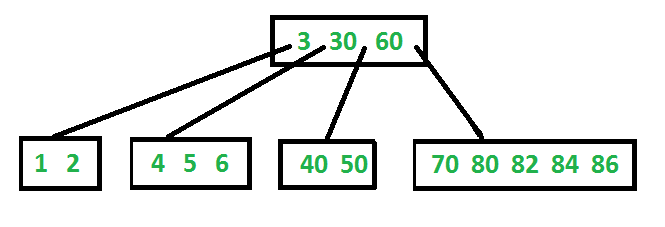
Contoh Min-Heap :

Aplikasi Heap :
Priority Queue
Temukan Algoritma (menemukan min / max elemen, median, k-terbesar elemen, dll).
Algoritma Dijkstra (menemukan jalan terpendek dalam grafik)
Prim Algoritma (menemukan pohon spanning minimum)
Heap Sort
O (n.lg (n)) algoritma.
Implementasi Array :
Tumpukan biasanya diimplementasikan dalam sebuah array.
Unsur-unsur yang disimpan secara berurutan dari indeks 1 sampai N dari atas ke bawah dan dari kiri ke simpul kanan pohon.
Akar disimpan dalam indeks 1
(Kita membiarkan indeks 0 kosong / tidak terpakai, untuk tujuan kenyamanan).

Insertion Min-Heap
 insert new node(20)
insert new node(20) insert new node(5)
insert new node(5) (continue)
(continue)
Deletion Min-Heap
Di sini kita hanya perhatian dengan penghapusan elemen terkecil yang terletak pada akar.
Ganti root dengan elemen terakhir dari tumpukan.
Menurunkan jumlah elemen dalam tumpukan.
akar Downheap (memperbaiki properti tumpukan nya).
 delete node(7)
delete node(7) (continue)
(continue)
Heap Complexity
•find-min : O(1)
•insert : O(log(n))
•delete-min :
O(log(n))
Menyisipkan dan menghapus-min tergantung pada tinggi pohon, yang
adalah log (n), ketinggian pohon biner lengkap.
Max-Heap
Unsur setiap node lebih besar dari elemen anak nya.
Ini menyiratkan bahwa elemen terbesar terletak pada akar pohon.
Max-tumpukan
memegang prinsip yang sama seperti min-heap dan dapat digunakan untuk
membuat antrian prioritas yang perlu menemukan elemen terbesar bukan
yang terkecil.
Min-Max Heap
Kondisi tumpukan bergantian antara minimum dan tingkat maksimum untuk tingkat
Setiap elemen di bahkan tingkat / aneh lebih kecil dari semua anak-anaknya (min-level).
Setiap elemen pada aneh / bahkan tingkat lebih besar dari semua anak-anaknya (max-level).
Tujuan
dari min-max heap adalah untuk memungkinkan kita untuk menemukan kedua
elemen terkecil dan terbesar dari tumpukan pada saat yang sama.

TRIES
Tries (prefix tree) adalah ordered tree data structure yang
digunakan untuk menyimpan array asosiatif (biasanya string)
TRIE berasal dari kata reTRIEval, karena TRIES dapat
menemukan satu kata dalam kamus dengan hanya awalan kata.
harshing
Hashing adalah transformasi dari
string karakter menjadi nilai panjang biasanya lebih pendek atau kunci
yang mewakili string asli.
Hashing digunakan untuk indeks dan
mengambil item dalam database karena lebih cepat untuk menemukan item
menggunakan kunci hash lebih pendek daripada untuk menemukannya
menggunakan nilai asli
HASH TABLE
tabel hash adalah tabel (array) di mana kita menyimpan string asli.
Indeks meja adalah kunci hash sementara nilai adalah string asli.
Ukuran tabel hash biasanya beberapa kali lipat lebih rendah dari jumlah
total kemungkinan string, sehingga beberapa string yang mungkin memiliki
hash-key yang sama.
Sebagai contoh, ada 267 (8031810176) string dengan panjang 7 terdiri dari huruf kecil saja.